
In a multi-region deployment, follow-the-workload is the default pattern for tables that use no other pattern. In general, this default pattern is a good choice only for tables with the following requirements:
- The table is active mostly in one region at a time, e.g., following the sun.
- In the active region, read latency must be low, but write latency can be higher.
- In non-active regions, both read and write latency can be higher.
- Table data must remain available during a region failure.
If read performance is your main focus for a table, but you want low-latency reads everywhere instead of just in the most active region, consider the Duplicate Indexes or Follower Reads pattern.
Prerequisites
Fundamentals
- Multi-region topology patterns are almost always table-specific.
- Review how data is replicated and distributed across a cluster, and how this affects performance. It is especially important to understand the concept of the "leaseholder". For a summary, see Reads and Writes in CockroachDB. For a deeper dive, see the CockroachDB Architecture documentation.
- Review the concept of locality, which makes CockroachDB aware of the location of nodes and able to intelligently place and balance data based on how you define replication controls.
- Review the recommendations and requirements in our Production Checklist.
- This topology doesn't account for hardware specifications, so be sure to follow our hardware recommendations and perform a POC to size hardware for your use case.
- Adopt relevant SQL Best Practices to ensure optimal performance.
Cluster setup
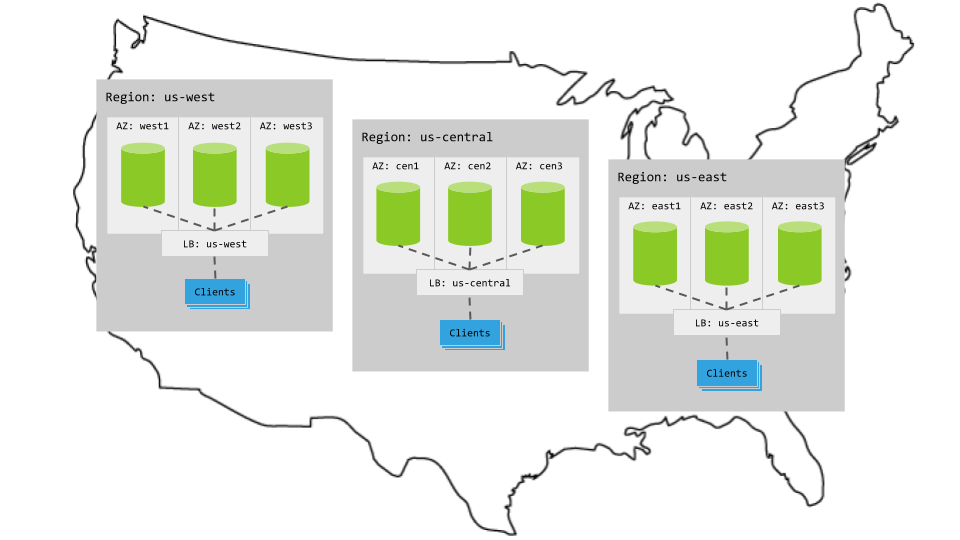
Each multi-region topology pattern assumes the following setup:
Hardware
3 regions
Per region, 3+ AZs with 3+ VMs evenly distributed across them
Region-specific app instances and load balancers
- Each load balancer redirects to CockroachDB nodes in its region.
- When CockroachDB nodes are unavailable in a region, the load balancer redirects to nodes in other regions.
Cluster
Each node is started with the --locality flag specifying its region and AZ combination. For example, the following command starts a node in the west1 AZ of the us-west region:
$ cockroach start \
--locality=region=us-west,zone=west1 \
--certs-dir=certs \
--advertise-addr=<node1 internal address> \
--join=<node1 internal address>:26257,<node2 internal address>:26257,<node3 internal address>:26257 \
--cache=.25 \
--max-sql-memory=.25 \
--background
Configuration
Aside from deploying a cluster across three regions properly, with each node started with the --locality flag specifying its region and AZ combination, this pattern requires no extra configuration. CockroachDB will balance the replicas for a table across the three regions and will assign the range lease to the replica in the region with the greatest demand at any given time (the follow-the-workload feature). This means that read latency in the active region will be low while read latency in other regions will be higher due to having to leave the region to reach the leaseholder. Write latency will be higher as well due to always involving replicas in multiple regions.
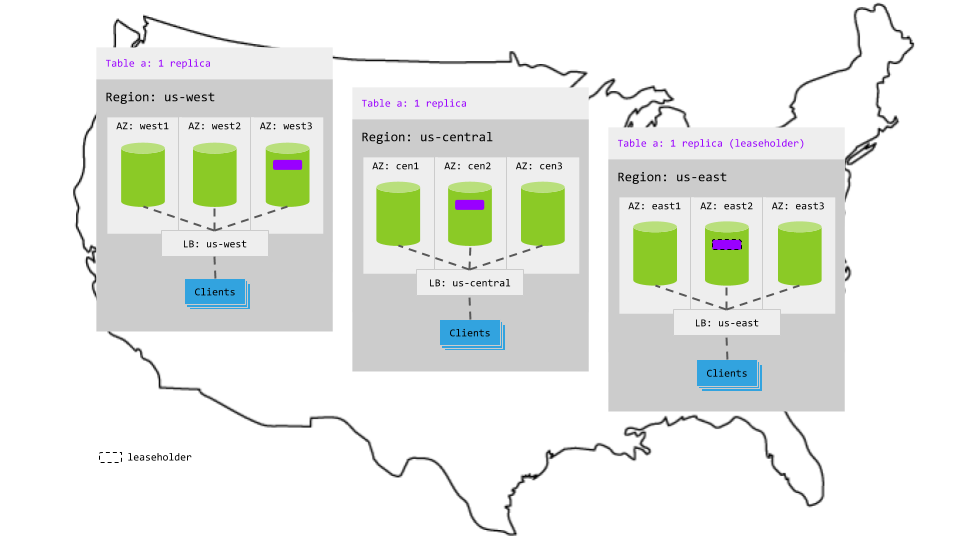
This pattern is also used by system ranges containing important internal data.
Characteristics
Latency
Reads
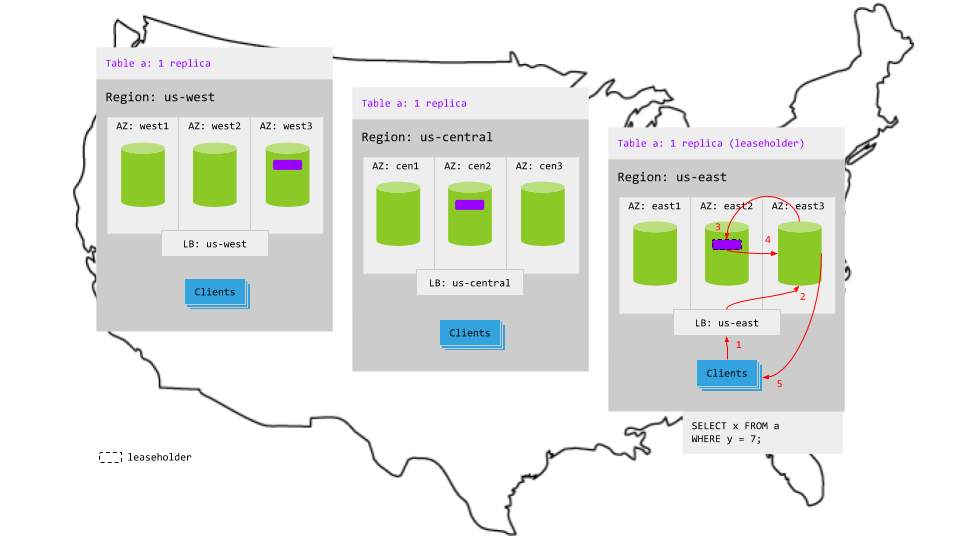
Reads in the region with the most demand will access the local leaseholder and, therefore, never leave the region. This makes read latency very low in the currently most active region. Reads in other regions, however, will be routed to the leaseholder in a different region and, thus, read latency will be higher.
For example, in the animation below, the most active region is us-east and, thus, the table's leaseholder is in that region:
- The read request in
us-eastreaches the regional load balancer. - The load balancer routes the request to a gateway node.
- The gateway node routes the request to the leaseholder replica.
- The leaseholder retrieves the results and returns to the gateway node.
- The gateway node returns the results to the client. In this case, reads in the
us-eastremain in the region and are lower-latency than reads in other regions.
Writes
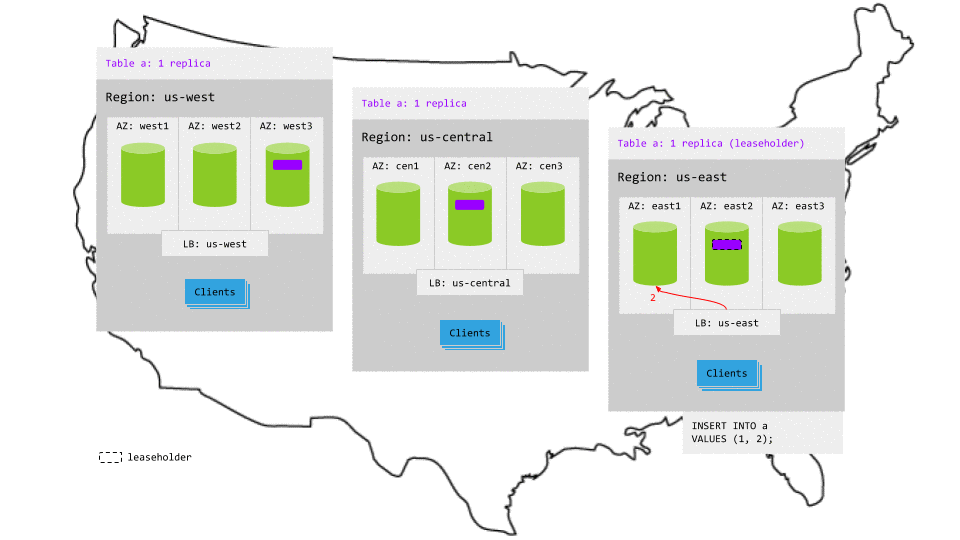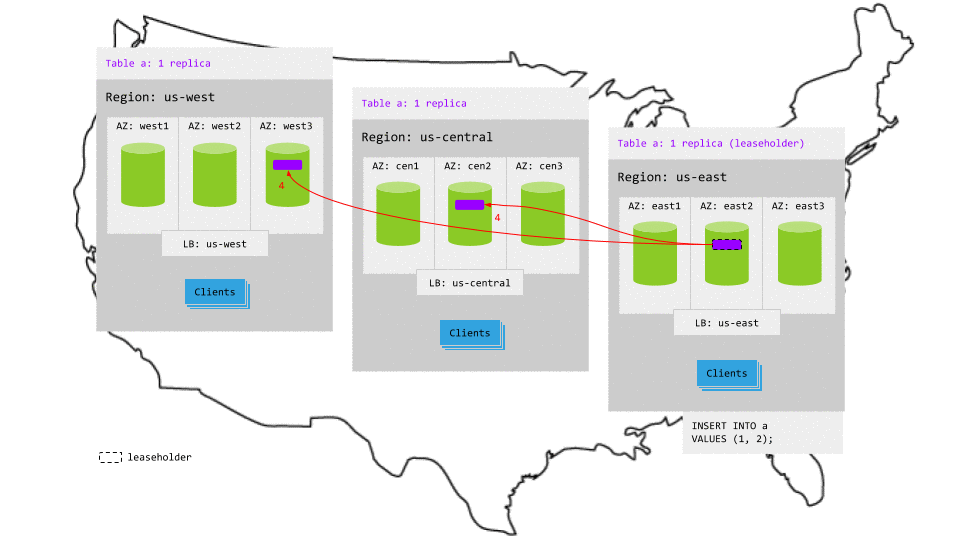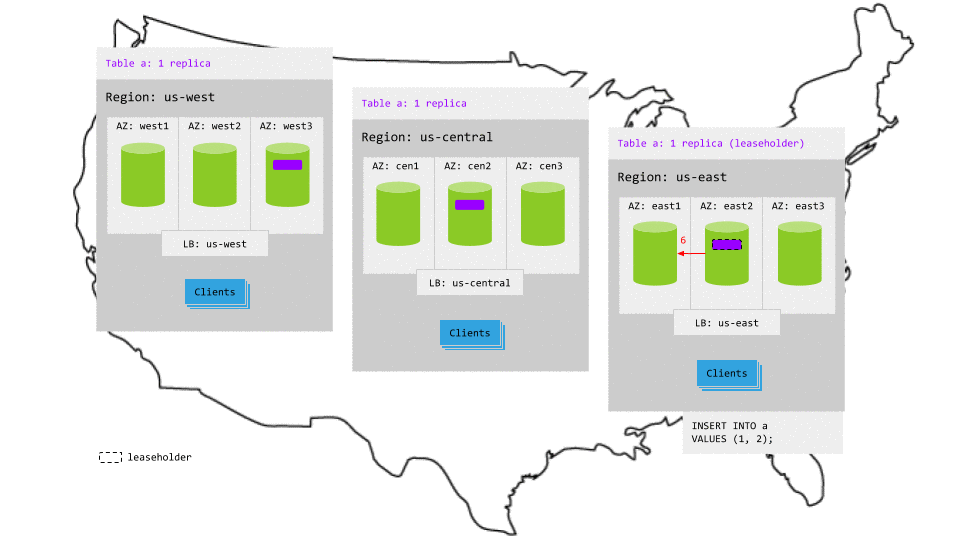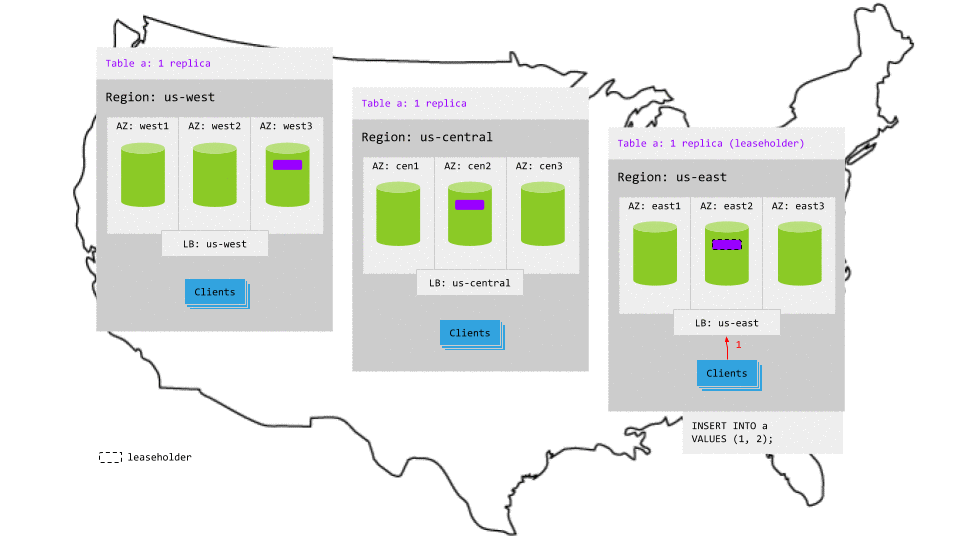
The replicas for the table are spread across all 3 regions, so writes involve multiple network hops across regions to achieve consensus. This increases write latency significantly.
For example, in the animation below, assuming the most active region is still us-east:
- The write request in
us-eastreaches the regional load balancer. - The load balancer routes the request to a gateway node.
- The gateway node routes the request to the leaseholder replica.
- While the leaseholder appends the write to its Raft log, it notifies its follower replicas.
- As soon as one follower has appended the write to its Raft log (and thus a majority of replicas agree based on identical Raft logs), it notifies the leaseholder and the write is committed on the agreeing replicas.
- The leaseholders then return acknowledgement of the commit to the gateway node.
- The gateway node returns the acknowledgement to the client.
Resiliency
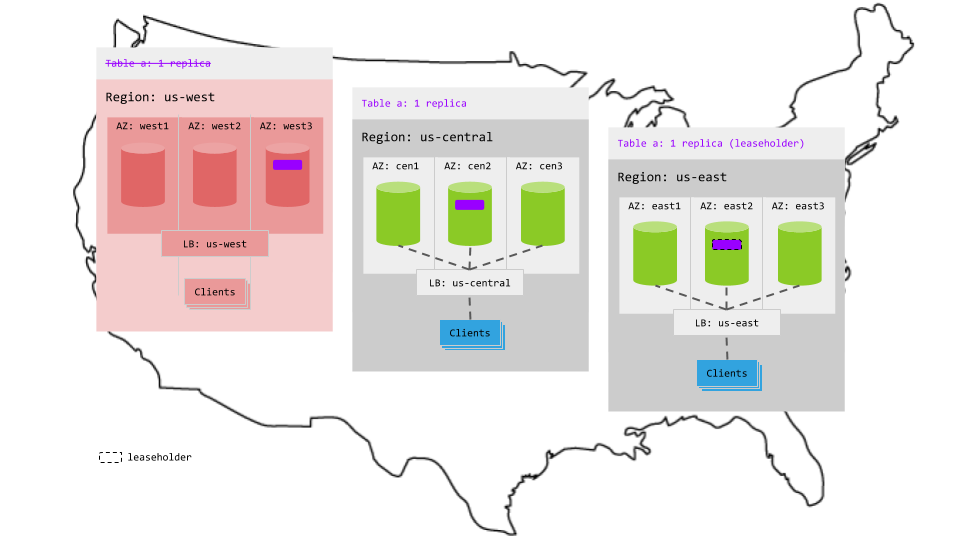
Because this pattern balances the replicas for the table across regions, one entire region can fail without interrupting access to the table:
See also
-
- Single-region
- Multi-region
Was this helpful?