
This page shows you how to manually deploy a secure multi-node CockroachDB cluster on Amazon's AWS EC2 platform, using AWS's managed load balancing service to distribute client traffic.
After setting up the AWS network, clock synchronization, and load balancing, it should take approximately 20 minutes to complete the deployment. This is based on initializing a three-node CockroachDB cluster in a single AWS region and running our sample workload.
If you are only testing CockroachDB, or you are not concerned with protecting network communication with TLS encryption, you can use an insecure cluster instead. Select Insecure above for instructions.
To deploy a free CockroachDB Cloud cluster instead of running CockroachDB yourself, see the Quickstart.
If you need a license to use Enterprise features, obtain a private offer link on the AWS Marketplace or see CockroachDB Pricing to learn about custom pricing.
Before you begin
Requirements
You must have CockroachDB installed locally. This is necessary for generating and managing your deployment's certificates.
You must have SSH access to each machine. This is necessary for distributing and starting CockroachDB binaries.
Your network configuration must allow TCP communication on the following ports:
26257for intra-cluster and client-cluster communication8080to expose your DB Console
Carefully review the Production Checklist, including supported hardware and software, and the recommended Topology Patterns.
Do not run multiple node processes on the same VM or machine. This defeats CockroachDB's replication and causes the system to be a single point of failure. Instead, start each node on a separate VM or machine.
To start a node with multiple disks or SSDs, you can use either of these approaches:
- Configure the disks or SSDs as a single RAID volume, then pass the RAID volume to the
--storeflag when starting thecockroachprocess on the node. - Provide a separate
--storeflag for each disk when starting thecockroachprocess on the node. For more details about stores, see Start a Node.
Warning:If you start a node with multiple--storeflags, it is not possible to scale back down to only using a single store on the node. Instead, you must decommission the node and start a new node with the updated--store.- Configure the disks or SSDs as a single RAID volume, then pass the RAID volume to the
When starting each node, use the
--localityflag to describe the node's location, for example,--locality=region=west,zone=us-west-1. The key-value pairs should be ordered from most to least inclusive, and the keys and order of key-value pairs must be the same on all nodes.When deploying in a single availability zone:
- To be able to tolerate the failure of any 1 node, use at least 3 nodes with the
default3-way replication factor. In this case, if 1 node fails, each range retains 2 of its 3 replicas, a majority. - To be able to tolerate 2 simultaneous node failures, use at least 5 nodes and increase the
defaultreplication factor for user data to 5. The replication factor for important internal data is 5 by default, so no adjustments are needed for internal data. In this case, if 2 nodes fail at the same time, each range retains 3 of its 5 replicas, a majority.
- To be able to tolerate the failure of any 1 node, use at least 3 nodes with the
When deploying across multiple availability zones:
- To be able to tolerate the failure of 1 entire AZ in a region, use at least 3 AZs per region and set
--localityon each node to spread data evenly across regions and AZs. In this case, if 1 AZ goes offline, the 2 remaining AZs retain a majority of replicas. - To ensure that ranges are split evenly across nodes, use the same number of nodes in each AZ. This is to avoid overloading any nodes with excessive resource consumption.
- To be able to tolerate the failure of 1 entire AZ in a region, use at least 3 AZs per region and set
When deploying across multiple regions:
- To be able to tolerate the failure of 1 entire region, use at least 3 regions.
CockroachDB is supported in all AWS regions.
Recommendations
Decide how you want to access your DB Console:
Access Level Description Partially open Set a firewall rule to allow only specific IP addresses to communicate on port 8080.Completely open Set a firewall rule to allow all IP addresses to communicate on port 8080.Completely closed Set a firewall rule to disallow all communication on port 8080. In this case, a machine with SSH access to a node could use an SSH tunnel to access the DB Console.You should have familiarity with configuring the following AWS components:
All Amazon EC2 instances running CockroachDB should be members of the same security group. For an example, see AWS architecture.
Follow the AWS IAM best practices to harden the AWS environment. Use roles to grant access to the deployment, following a policy of least privilege.
The AWS root user is not necessary.
Review the AWS Config service limits and contact AWS support to request a quota increase, if necessary.
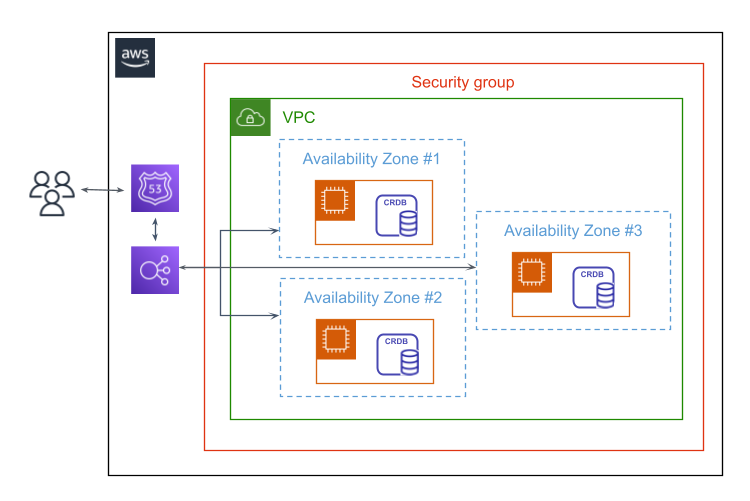
AWS architecture
In this basic deployment, 3 CockroachDB nodes are each deployed on an Amazon EC2 instance across 3 availability zones. These are grouped within a single VPC and security group. Users are routed to the cluster via Amazon Route 53 (which is not used in this tutorial) and a load balancer.
Step 1. Create instances
Open the Amazon EC2 console and launch an instance for each node you plan to have in your cluster. If you plan to run our sample workload against the cluster, create a separate instance for that workload.
Run at least 3 nodes to ensure survivability.
Your instances will rely on Amazon Time Sync Service for clock synchronization. When choosing an AMI, note that some machines are preconfigured to use Amazon Time Sync Service (e.g., Amazon Linux AMIs) and others are not.
Use general-purpose
m6iorm6aVMs with SSD-backed EBS volumes. For example, Cockroach Labs has usedm6i.2xlargefor performance benchmarking. If your workload requires high throughput, use network-optimizedm5ninstances. To simulate bare-metal deployments, usem5dwith SSD Instance Store volumes.m5andm5ainstances, and compute-optimizedc5,c5a, andc5ninstances, are also acceptable.
Warning:CockroachDB does not support Arm-based
m6ginstances.Do not use burstable performance instances, which limit the load on a single core.
Note the ID of the VPC you select. You will need to look up its IP range when setting inbound rules for your security group.
Make sure all your instances are in the same security group.
- If you are creating a new security group, add the inbound rules from the next step. Otherwise note the ID of the security group.
When creating the instance, you will be prompted to specify an EC2 key pair. For more information on key pairs, see the AWS documentation. These are used to securely connect to your instances and should be encrypted (e.g.,
ssh-keygen -p -f $keypairfilein Linux).
For more details, see Hardware Recommendations and Cluster Topology.
Step 2. Configure your network
Add Custom TCP inbound rules to your security group to allow TCP communication on two ports:
26257for inter-node and client-node communication. This enables the nodes to work as a cluster, the load balancer to route traffic to the nodes, and applications to connect to the load balancer.8080for exposing the DB Console to the user, and for routing the load balancer to the health check endpoint.
Inter-node and load balancer-node communication
| Field | Value |
|---|---|
| Port Range | 26257 |
| Source | The ID of your security group (e.g., sg-07ab277a) |
Application data
| Field | Value |
|---|---|
| Port Range | 26257 |
| Source | Your application's IP ranges |
DB Console
| Field | Value |
|---|---|
| Port Range | 8080 |
| Source | Your network's IP ranges |
You can set your network IP by selecting "My IP" in the Source field.
Load balancer-health check communication
| Field | Value |
|---|---|
| Port Range | 8080 |
| Source | The IP range of your VPC in CIDR notation (e.g., 10.12.0.0/16) |
To get the IP range of a VPC, open the Amazon VPC console and find the VPC listed in the section called Your VPCs.
Load balancer-health check communication
| Field | Value |
|---|---|
| Port Range | 8080 |
| Source | The IP range of your VPC in CIDR notation (e.g., 10.12.0.0/16) |
To get the IP range of a VPC, open the Amazon VPC console and find the VPC listed in the section called Your VPCs.
Step 3. Synchronize clocks
CockroachDB requires moderate levels of clock synchronization to preserve data consistency. For this reason, when a node detects that its clock is out of sync with at least half of the other nodes in the cluster by 80% of the maximum offset allowed (500ms by default), it spontaneously shuts down. This avoids the risk of consistency anomalies, but it's best to prevent clocks from drifting too far in the first place by running clock synchronization software on each node.
Amazon provides the Amazon Time Sync Service, which uses a fleet of satellite-connected and atomic reference clocks in each AWS Region to deliver accurate current time readings. The service also smears the leap second.
- Configure each AWS instance to use the internal Amazon Time Sync Service.
- Per the above instructions, ensure that
etc/chrony.confon the instance contains the lineserver 169.254.169.123 prefer iburst minpoll 4 maxpoll 4and that otherserverorpoollines are commented out. - To verify that Amazon Time Sync Service is being used, run
chronyc sources -vand check for a line containing* 169.254.169.123. The*denotes the preferred time server.
- Per the above instructions, ensure that
- If you plan to run a hybrid cluster across GCE and other cloud providers or environments, note that all of the nodes must be synced to the same time source, or to different sources that implement leap second smearing in the same way. See the Production Checklist for details.
Step 4. Set up load balancing
Each CockroachDB node is an equally suitable SQL gateway to your cluster, but to ensure client performance and reliability, it's important to use load balancing:
Performance: Load balancers spread client traffic across nodes. This prevents any one node from being overwhelmed by requests and improves overall cluster performance (queries per second).
Reliability: Load balancers decouple client health from the health of a single CockroachDB node. In cases where a node fails, the load balancer redirects client traffic to available nodes.
AWS offers fully-managed load balancing to distribute traffic between instances.
- Add AWS load balancing. Be sure to:
- Select a Network Load Balancer and use the ports we specify below.
- Select the VPC and all availability zones of your instances. This is important, as you cannot change the availability zones once the load balancer is created. The availability zone of an instance is determined by its subnet, found by inspecting the instance in the Amazon EC2 Console.
- Set the load balancer port to 26257.
- Create a new target group that uses TCP port 26257. Traffic from your load balancer is routed to this target group, which contains your instances.
- Configure health checks to use HTTP port 8080 and path
/health?ready=1. This health endpoint ensures that load balancers do not direct traffic to nodes that are live but not ready to receive requests. - Register your instances with the target group you created, specifying port 26257. You can add and remove instances later.
- To test load balancing and connect your application to the cluster, you will need the provisioned internal (private) IP address for the load balancer. To find this, open the Network Interfaces section of the Amazon EC2 console and look up the load balancer by its name.
Step 5. Generate certificates
You can use cockroach cert commands, openssl commands, or Auto TLS cert generation (alpha) to generate security certificates. This section features the cockroach cert commands.
Locally, you'll need to create the following certificates and keys:
- A certificate authority (CA) key pair (
ca.crtandca.key). - A node key pair for each node, issued to its IP addresses and any common names the machine uses, as well as to the IP addresses and common names for machines running load balancers.
- A client key pair for the
rootuser. You'll use this to run a sample workload against the cluster as well as somecockroachclient commands from your local machine.
Install CockroachDB on your local machine, if you haven't already.
Create two directories:
$ mkdir certs$ mkdir my-safe-directorycerts: You'll generate your CA certificate and all node and client certificates and keys in this directory and then upload some of the files to your nodes.my-safe-directory: You'll generate your CA key in this directory and then reference the key when generating node and client certificates. After that, you'll keep the key safe and secret; you will not upload it to your nodes.
Create the CA certificate and key:
$ cockroach cert create-ca \ --certs-dir=certs \ --ca-key=my-safe-directory/ca.keyCreate the certificate and key for the first node, issued to all common names you might use to refer to the node as well as to the load balancer instances:
$ cockroach cert create-node \ <node1 internal IP address> \ <node1 external IP address> \ <node1 hostname> \ <other common names for node1> \ localhost \ 127.0.0.1 \ <load balancer IP address> \ <load balancer hostname> \ <other common names for load balancer instances> \ --certs-dir=certs \ --ca-key=my-safe-directory/ca.keyUpload the CA certificate and node certificate and key to the first node:
$ ssh-add /path/<key file>.pem$ ssh <username>@<node1 DNS name> "mkdir certs"$ scp certs/ca.crt \ certs/node.crt \ certs/node.key \ <username>@<node1 DNS name>:~/certsDelete the local copy of the node certificate and key:
$ rm certs/node.crt certs/node.keyNote:This is necessary because the certificates and keys for additional nodes will also be named
node.crtandnode.key. As an alternative to deleting these files, you can run the nextcockroach cert create-nodecommands with the--overwriteflag.Create the certificate and key for the second node, issued to all common names you might use to refer to the node as well as to the load balancer instances:
$ cockroach cert create-node \ <node2 internal IP address> \ <node2 external IP address> \ <node2 hostname> \ <other common names for node2> \ localhost \ 127.0.0.1 \ <load balancer IP address> \ <load balancer hostname> \ <other common names for load balancer instances> \ --certs-dir=certs \ --ca-key=my-safe-directory/ca.keyUpload the CA certificate and node certificate and key to the second node:
$ ssh <username>@<node2 DNS name> "mkdir certs"$ scp certs/ca.crt \ certs/node.crt \ certs/node.key \ <username>@<node2 DNS name>:~/certsRepeat steps 6 - 8 for each additional node.
Create a client certificate and key for the
rootuser:$ cockroach cert create-client \ root \ --certs-dir=certs \ --ca-key=my-safe-directory/ca.keyUpload the CA certificate and client certificate and key to the machine where you will run a sample workload:
$ ssh <username>@<workload address> "mkdir certs"$ scp certs/ca.crt \ certs/client.root.crt \ certs/client.root.key \ <username>@<workload address>:~/certsIn later steps, you'll also use the
rootuser's certificate to runcockroachclient commands from your local machine. If you might also want to runcockroachclient commands directly on a node (e.g., for local debugging), you'll need to copy therootuser's certificate and key to that node as well.
On accessing the DB Console in a later step, your browser will consider the CockroachDB-created certificate invalid and you’ll need to click through a warning message to get to the UI. You can avoid this issue by using a certificate issued by a public CA.
Step 6. Start nodes
You can start the nodes manually or automate the process using systemd.
For each initial node of your cluster, complete the following steps:
After completing these steps, nodes will not yet be live. They will complete the startup process and join together to form a cluster as soon as the cluster is initialized in the next step.
SSH to the machine where you want the node to run.
Download the CockroachDB archive for Linux, and extract the binary:
$ curl https://binaries.cockroachdb.com/cockroach-v23.2.6.linux-amd64.tgz \ | tar -xzCopy the binary into the
PATH:$ cp -i cockroach-v23.2.6.linux-amd64/cockroach /usr/local/bin/If you get a permissions error, prefix the command with
sudo.CockroachDB uses custom-built versions of the GEOS libraries. Copy these libraries to the location where CockroachDB expects to find them:
$ mkdir -p /usr/local/lib/cockroach$ cp -i cockroach-v23.2.6.linux-amd64/lib/libgeos.so /usr/local/lib/cockroach/$ cp -i cockroach-v23.2.6.linux-amd64/lib/libgeos_c.so /usr/local/lib/cockroach/If you get a permissions error, prefix the command with
sudo.Run the
cockroach startcommand:$ cockroach start \ --certs-dir=certs \ --advertise-addr=<node1 address> \ --join=<node1 address>,<node2 address>,<node3 address> \ --cache=.25 \ --max-sql-memory=.25 \ --backgroundThis command primes the node to start, using the following flags:
Flag Description --certs-dirSpecifies the directory where you placed the ca.crtfile and thenode.crtandnode.keyfiles for the node.--advertise-addrSpecifies the IP address/hostname and port to tell other nodes to use. The port number can be omitted, in which case it defaults to 26257.
This value must route to an IP address the node is listening on (with--listen-addrunspecified, the node listens on all IP addresses).
In some networking scenarios, you may need to use--advertise-addrand/or--listen-addrdifferently. For more details, see Networking.--joinIdentifies the address of 3-5 of the initial nodes of the cluster. These addresses should match the addresses that the target nodes are advertising. --cache--max-sql-memoryIncreases the node's cache size to 25% of available system memory to improve read performance. The capacity for in-memory SQL processing defaults to 25% of system memory but can be raised, if necessary, to increase the number of simultaneous client connections allowed by the node as well as the node's capacity for in-memory processing of rows when using ORDER BY,GROUP BY,DISTINCT, joins, and window functions. For more details, see Cache and SQL Memory Size.--backgroundStarts the node in the background so you gain control of the terminal to issue more commands. When deploying across multiple datacenters, or when there is otherwise high latency between nodes, it is recommended to set
--localityas well. It is also required to use certain Enterprise features. For more details, see Locality.For other flags not explicitly set, the command uses default values. For example, the node stores data in
--store=cockroach-dataand binds DB Console HTTP requests to--http-addr=<node1 address>:8080. To set these options manually, see Start a Node.Repeat these steps for each additional node that you want in your cluster.
For each initial node of your cluster, complete the following steps:
After completing these steps, nodes will not yet be live. They will complete the startup process and join together to form a cluster as soon as the cluster is initialized in the next step.
SSH to the machine where you want the node to run. Ensure you are logged in as the
rootuser.Download the CockroachDB archive for Linux, and extract the binary:
$ curl https://binaries.cockroachdb.com/cockroach-v23.2.6.linux-amd64.tgz \ | tar -xzCopy the binary into the
PATH:$ cp -i cockroach-v23.2.6.linux-amd64/cockroach /usr/local/bin/If you get a permissions error, prefix the command with
sudo.CockroachDB uses custom-built versions of the GEOS libraries. Copy these libraries to the location where CockroachDB expects to find them:
$ mkdir -p /usr/local/lib/cockroach$ cp -i cockroach-v23.2.6.linux-amd64/lib/libgeos.so /usr/local/lib/cockroach/$ cp -i cockroach-v23.2.6.linux-amd64/lib/libgeos_c.so /usr/local/lib/cockroach/If you get a permissions error, prefix the command with
sudo.Create the Cockroach directory:
$ mkdir /var/lib/cockroachCreate a Unix user named
cockroach:$ useradd cockroachMove the
certsdirectory to thecockroachdirectory.$ mv certs /var/lib/cockroach/Change the ownership of the
cockroachdirectory to the usercockroach:$ chown -R cockroach /var/lib/cockroachDownload the sample configuration template and save the file in the
/etc/systemd/system/directory:curl -o securecockroachdb.service https://raw.githubusercontent.com/cockroachdb/docs/main/src/current/_includes/v23.2/prod-deployment/securecockroachdb.serviceAlternatively, you can create the file yourself and copy the script into it:
[Unit] Description=Cockroach Database cluster node Requires=network.target [Service] Type=notify WorkingDirectory=/var/lib/cockroach ExecStart=/usr/local/bin/cockroach start --certs-dir=certs --advertise-addr=<node1 address> --join=<node1 address>,<node2 address>,<node3 address> --cache=.25 --max-sql-memory=.25 TimeoutStopSec=300 Restart=always RestartSec=10 StandardOutput=syslog StandardError=syslog SyslogIdentifier=cockroach User=cockroach [Install] WantedBy=default.targetIn the sample configuration template, specify values for the following flags:
Flag Description --advertise-addrSpecifies the IP address/hostname and port to tell other nodes to use. The port number can be omitted, in which case it defaults to 26257.
This value must route to an IP address the node is listening on (with--listen-addrunspecified, the node listens on all IP addresses).
In some networking scenarios, you may need to use--advertise-addrand/or--listen-addrdifferently. For more details, see Networking.--joinIdentifies the address of 3-5 of the initial nodes of the cluster. These addresses should match the addresses that the target nodes are advertising. When deploying across multiple datacenters, or when there is otherwise high latency between nodes, it is recommended to set
--localityas well. It is also required to use certain Enterprise features. For more details, see Locality.For other flags not explicitly set, the command uses default values. For example, the node stores data in
--store=cockroach-dataand binds DB Console HTTP requests to--http-addr=localhost:8080. To set these options manually, see Start a Node.Start the CockroachDB cluster:
$ systemctl start securecockroachdbConfigure
systemdto start CockroachDB automatically after a reboot:systemctl enable securecockroachdbRepeat these steps for each additional node that you want in your cluster.
systemd handles node restarts in case of node failure. To stop a node without systemd restarting it, run systemctl stop securecockroachdb
Step 7. Initialize the cluster
On your local machine, run the cockroach init command to complete the node startup process and have them join together as a cluster:
$ cockroach init --certs-dir=certs --host=<address of any node on --join list>
After running this command, each node prints helpful details to the standard output, such as the CockroachDB version, the URL for the DB Console, and the SQL URL for clients.
Step 8. Test your cluster
CockroachDB replicates and distributes data behind-the-scenes and uses a Gossip protocol to enable each node to locate data across the cluster. Once a cluster is live, any node can be used as a SQL gateway.
When using a load balancer, you should issue commands directly to the load balancer, which then routes traffic to the nodes.
Use the built-in SQL client locally as follows:
On your local machine, launch the built-in SQL client, with the
--hostflag set to the address of the load balancer:$ cockroach sql --certs-dir=certs --host=<address of load balancer>Create a
securenodetestdatabase:> CREATE DATABASE securenodetest;View the cluster's databases, which will include
securenodetest:> SHOW DATABASES;+--------------------+ | Database | +--------------------+ | crdb_internal | | information_schema | | securenodetest | | pg_catalog | | system | +--------------------+ (5 rows)Use
\qto exit the SQL shell.
Step 9. Run a sample workload
CockroachDB comes with a number of built-in workloads for simulating client traffic. This step features CockroachDB's version of the TPC-C workload.
Be sure that you have configured your network to allow traffic from the application to the load balancer. In this case, you will run the sample workload on one of your machines. The traffic source should therefore be the internal (private) IP address of that machine.
For comprehensive guidance on benchmarking CockroachDB with TPC-C, refer to Performance Benchmarking.
SSH to the machine where you want to run the sample TPC-C workload.
This should be a machine that is not running a CockroachDB node, and it should already have a
certsdirectory containingca.crt,client.root.crt, andclient.root.keyfiles.Download the CockroachDB archive for Linux, and extract the binary:
$ curl https://binaries.cockroachdb.com/cockroach-v23.2.6.linux-amd64.tgz \ | tar -xzCopy the binary into the
PATH:$ cp -i cockroach-v23.2.6.linux-amd64/cockroach /usr/local/bin/If you get a permissions error, prefix the command with
sudo.Use the
cockroach workloadcommand to load the initial schema and data, pointing it at the IP address of the load balancer:$ cockroach workload init tpcc \ 'postgresql://root@<IP ADDRESS OF LOAD BALANCER>:26257/tpcc?sslmode=verify-full&sslrootcert=certs/ca.crt&sslcert=certs/client.root.crt&sslkey=certs/client.root.key'Use the
cockroach workloadcommand to run the workload for 10 minutes:$ cockroach workload run tpcc \ --duration=10m \ 'postgresql://root@<IP ADDRESS OF LOAD BALANCER>:26257/tpcc?sslmode=verify-full&sslrootcert=certs/ca.crt&sslcert=certs/client.root.crt&sslkey=certs/client.root.key'You'll see per-operation statistics print to standard output every second:
_elapsed___errors__ops/sec(inst)___ops/sec(cum)__p50(ms)__p95(ms)__p99(ms)_pMax(ms) 1s 0 1443.4 1494.8 4.7 9.4 27.3 67.1 transfer 2s 0 1686.5 1590.9 4.7 8.1 15.2 28.3 transfer 3s 0 1735.7 1639.0 4.7 7.3 11.5 28.3 transfer 4s 0 1542.6 1614.9 5.0 8.9 12.1 21.0 transfer 5s 0 1695.9 1631.1 4.7 7.3 11.5 22.0 transfer 6s 0 1569.2 1620.8 5.0 8.4 11.5 15.7 transfer 7s 0 1614.6 1619.9 4.7 8.1 12.1 16.8 transfer 8s 0 1344.4 1585.6 5.8 10.0 15.2 31.5 transfer 9s 0 1351.9 1559.5 5.8 10.0 16.8 54.5 transfer 10s 0 1514.8 1555.0 5.2 8.1 12.1 16.8 transfer ...After the specified duration (10 minutes in this case), the workload will stop and you'll see totals printed to standard output:
_elapsed___errors_____ops(total)___ops/sec(cum)__avg(ms)__p50(ms)__p95(ms)__p99(ms)_pMax(ms)__result 600.0s 0 823902 1373.2 5.8 5.5 10.0 15.2 209.7Tip:For more
tpccoptions, usecockroach workload run tpcc --help. For details about other workloads built into thecockroachbinary, usecockroach workload --help.To monitor the load generator's progress, open the DB Console by pointing a browser to the address in the
adminfield in the standard output of any node on startup.Since the load generator is pointed at the load balancer, the connections will be evenly distributed across nodes. To verify this, click Metrics on the left, select the SQL dashboard, and then check the SQL Connections graph. You can use the Graph menu to filter the graph for specific nodes.
Step 10. Monitor the cluster
In the Target Groups section of the Amazon EC2 console, check the health of your instances by inspecting your target group and opening the Targets tab.
Despite CockroachDB's various built-in safeguards against failure, it is critical to actively monitor the overall health and performance of a cluster running in production and to create alerting rules that promptly send notifications when there are events that require investigation or intervention.
For details about available monitoring options and the most important events and metrics to alert on, see Monitoring and Alerting.
Step 11. Scale the cluster
Before adding a new node, create a new instance as you did earlier. Then generate and upload a certificate and key for the new node.
You can start the nodes manually or automate the process using systemd.
For each additional node you want to add to the cluster, complete the following steps:
SSH to the machine where you want the node to run.
Download the CockroachDB archive for Linux, and extract the binary:
curl -o cockroach-v23.2.6.linux-amd64.tgz https://binaries.cockroachdb.com/cockroach-v23.2.6.linux-amd64.tgz; tar xzvf cockroach-v23.2.6.linux-amd64.tgzCopy the binary into the
PATH:$ cp -i cockroach-v23.2.6.linux-amd64/cockroach /usr/local/bin/If you get a permissions error, prefix the command with
sudo.Run the
cockroach startcommand, passing the new node's address as the--advertise-addrflag and pointing--jointo the three existing nodes (also include--localityif you set it earlier).$ cockroach start \ --certs-dir=certs \ --advertise-addr=<node4 address> \ --join=<node1 address>,<node2 address>,<node3 address> \ --cache=.25 \ --max-sql-memory=.25 \ --backgroundUpdate your load balancer to recognize the new node.
For each additional node you want to add to the cluster, complete the following steps:
SSH to the machine where you want the node to run. Ensure you are logged in as the
rootuser.Download the CockroachDB archive for Linux, and extract the binary:
$ curl https://binaries.cockroachdb.com/cockroach-v23.2.6.linux-amd64.tgz \ | tar -xzCopy the binary into the
PATH:$ cp -i cockroach-v23.2.6.linux-amd64/cockroach /usr/local/bin/If you get a permissions error, prefix the command with
sudo.Create the Cockroach directory:
$ mkdir /var/lib/cockroachCreate a Unix user named
cockroach:$ useradd cockroachMove the
certsdirectory to thecockroachdirectory.$ mv certs /var/lib/cockroach/Change the ownership of the
cockroachdirectory to the usercockroach:$ chown -R cockroach /var/lib/cockroachDownload the sample configuration template:
curl -o securecockroachdb.service https://raw.githubusercontent.com/cockroachdb/docs/master/_includes/v23.2/prod-deployment/securecockroachdb.serviceAlternatively, you can create the file yourself and copy the script into it:
[Unit] Description=Cockroach Database cluster node Requires=network.target [Service] Type=notify WorkingDirectory=/var/lib/cockroach ExecStart=/usr/local/bin/cockroach start --certs-dir=certs --advertise-addr=<node1 address> --join=<node1 address>,<node2 address>,<node3 address> --cache=.25 --max-sql-memory=.25 TimeoutStopSec=300 Restart=always RestartSec=10 StandardOutput=syslog StandardError=syslog SyslogIdentifier=cockroach User=cockroach [Install] WantedBy=default.targetSave the file in the
/etc/systemd/system/directory.Customize the sample configuration template for your deployment:
Specify values for the following flags in the sample configuration template:
Flag Description --advertise-addrSpecifies the IP address/hostname and port to tell other nodes to use. The port number can be omitted, in which case it defaults to 26257.
This value must route to an IP address the node is listening on (with--listen-addrunspecified, the node listens on all IP addresses).
In some networking scenarios, you may need to use--advertise-addrand/or--listen-addrdifferently. For more details, see Networking.--joinIdentifies the address of 3-5 of the initial nodes of the cluster. These addresses should match the addresses that the target nodes are advertising. Repeat these steps for each additional node that you want in your cluster.
Step 12. Use the database
Now that your deployment is working, you can:
- Implement your data model.
- Create users and grant them privileges.
- Connect your application. Be sure to connect your application to the load balancer, not to a CockroachDB node.
- Take backups of your data.
You may also want to adjust the way the cluster replicates data. For example, by default, a multi-node cluster replicates all data 3 times; you can change this replication factor or create additional rules for replicating individual databases and tables differently. For more information, see Replication Controls.
When running a cluster of 5 nodes or more, it's safest to increase the replication factor for important internal data to 5, even if you do not do so for user data. For the cluster as a whole to remain available, the ranges for this internal data must always retain a majority of their replicas.
See also
- Production Checklist
- Manual Deployment
- Orchestrated Deployment
- Monitoring and Alerting
- Performance Benchmarking
- Performance Tuning
- Local Deployment
Was this helpful?